
AI
Jun 15, 2026
Understanding Differential Privacy: Part 2
A hands-on guide to DP-SGD: how it works, how VaultGemma uses it at LLM scale, and what private vs non-private training actually costs on CIFAR-10.
AI
Jan 15, 2026

Federated Learning: Framework and Fundamentals
Data Distribution Taxonomies
The Centralized Architecture
The Decentralized Architecture
Federated Averaging: The Foundation Algorithm
Security Concerns
Secure Aggregation via Masking
Federated Learning with Homomorphic Encryption
Multi-Party Computation for Federated Learning
Multiparty Homomorphic Encryption for Federated Learning
Verifiable Federated Learning with Zero-Knowledge Proofs
zkDFL: Verifiable Aggregation with Untrusted Servers
Verifiable FL with Untrusted Clients: Federify
Conclusion
The exponential growth of edge data generation has created a fundamental tension in modern machine learning. While centralized data aggregation enables powerful model training, it conflicts with privacy regulations, data sovereignty requirements, and the impracticality of transferring massive datasets. Federated learning resolves this by inverting the traditional workflow: instead of moving data to the model, we move the model to the data.
In federated learning, multiple parties collaboratively train a shared model while keeping data localized. A central coordinator distributes model parameters to clients, who train locally and return only model updates, gradients or weights. The server aggregates these updates to refine the global model, enabling healthcare institutions, financial organizations, and mobile devices to collaborate without exposing sensitive data.
However, naive implementations remain vulnerable. Model updates can be exploited through membership inference and model inversion attacks, while poisoning attacks can compromise integrity. These vulnerabilities necessitate a comprehensive cryptographic framework.
This article examines the cryptographic foundations for secure federated learning. We focus on horizontal federated learning (shared features, different samples). Our security framework addresses three requirements: confidentiality of updates, robustness against malicious participants, and verifiability of computations.
We explore homomorphic encryption, particularly partially homomorphic schemes like Paillier for resource efficiency, and fully homomorphic encryption for end-to-end privacy scenarios. We analyze secure multi-party computation protocols that distribute trust at the cost of communication overhead. Finally, we introduce zero-knowledge proofs for verifiable aggregation.
Federated learning enables multiple parties to collaboratively train a shared model while keeping training data distributed across participating devices or institutions. Rather than consolidating data centrally, the model travels to the data, trains locally, and only model updates return to a coordinating server. This approach addresses scenarios where data is privacy-sensitive or impractical to centralize: mobile devices, hospitals, and financial institutions can all participate in collaborative training without exposing raw datasets.
Federated learning systems are categorized by how data is distributed among participants:
Horizontal Federated Learning: Participants share the same feature space but have different sample ID spaces. This occurs when similar entities serve distinct populations: regional hospitals with different patient cohorts, banks in separate markets, or mobile devices owned by different users. Since all participants use identical feature representations, models aggregate naturally through parameter averaging.
Vertical Federated Learning: Datasets share the same sample ID space but differ in feature space. For example, a bank and e-commerce company in the same city have overlapping user sets, but the bank records financial behavior while e-commerce retains purchasing history. This asymmetric structure requires more complex secure aggregation protocols.
Federated Transfer Learning: Datasets differ in both feature space and sample space with minimal overlap. A common representation is learned using limited common samples and applied to predictions for samples with single-side features. This enables collaboration across related but distinct domains.
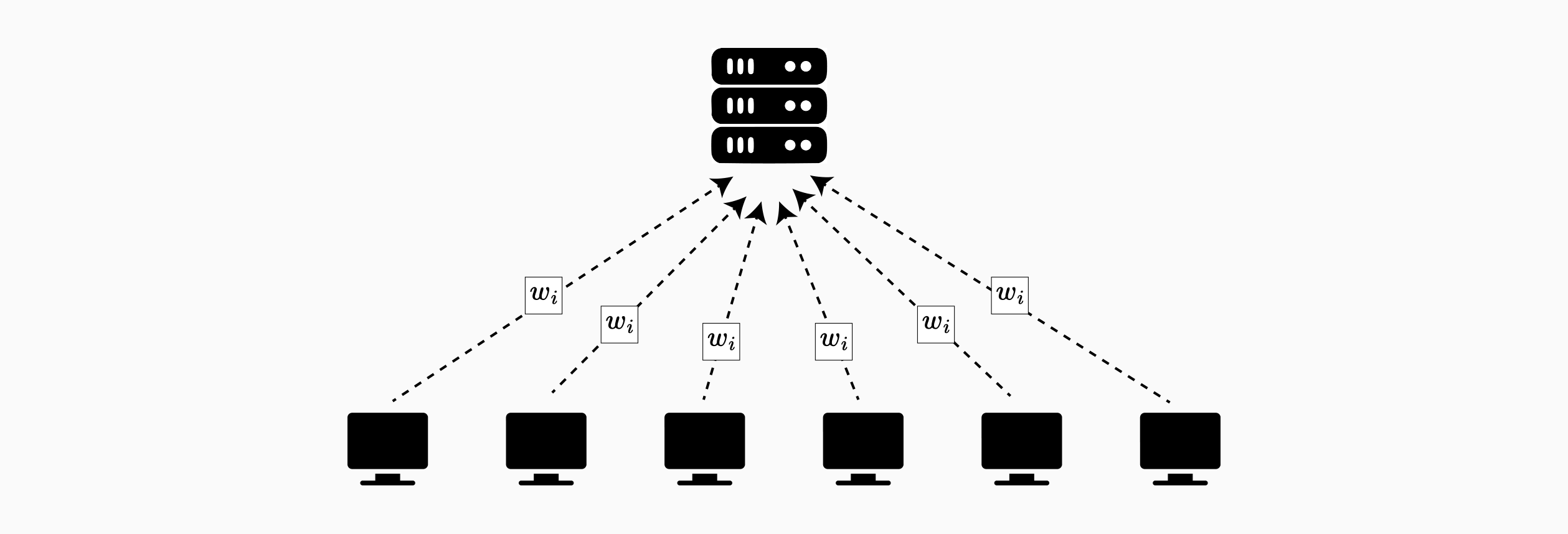
In centralized federated learning, a single coordinating server orchestrates training across participating clients. Training proceeds in iterative rounds with four phases: client selection, local training, update transmission, and global aggregation. The server samples a subset of clients each round to address bandwidth limitations and device availability. Selected clients receive current model parameters, perform local training on their private data, and transmit updates back to the server. The server aggregates these updates to produce an improved global model for the next round.
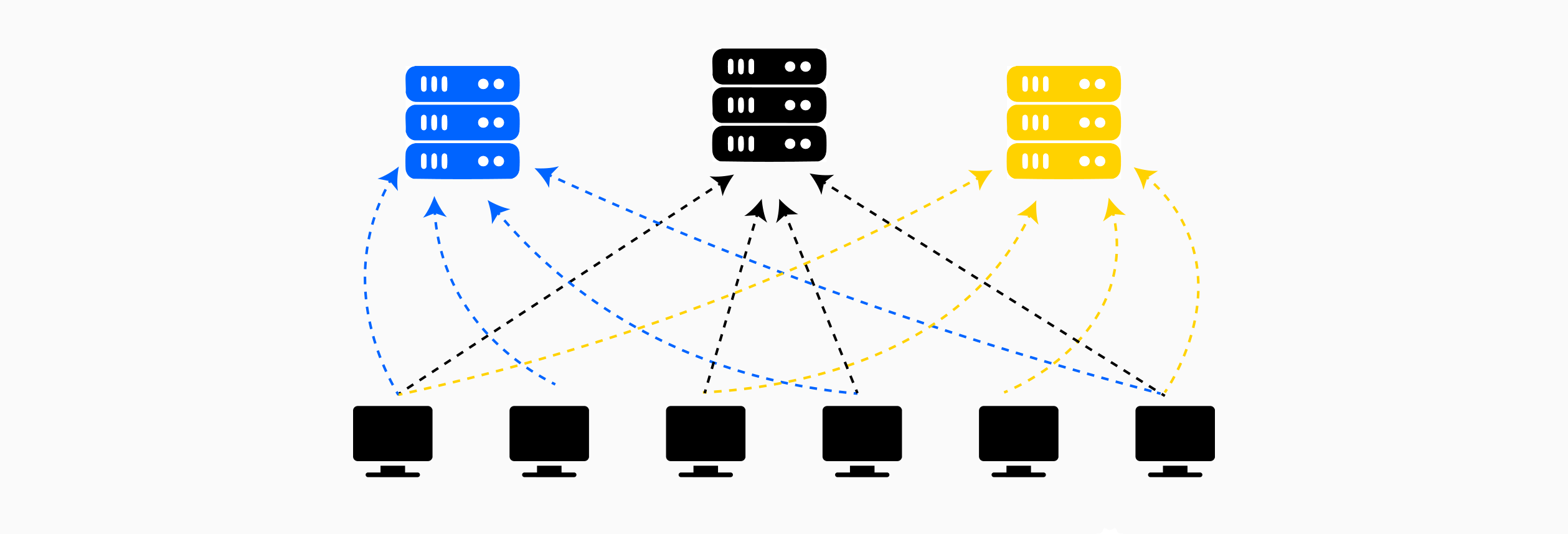
In decentralized federated learning, the central coordinator is replaced by a distributed coordination mechanism, typically implemented through blockchain smart contracts or peer-to-peer protocols. Rather than relying on a single trusted server, clients interact directly with an immutable ledger or distributed network that enforces the training protocol. Clients register their participation on-chain, submit encrypted or masked model updates to the blockchain, and the aggregation logic executes automatically within smart contracts. This architecture eliminates the single point of failure and removes the trust assumption on a central aggregator. However, decentralization introduces additional challenges: blockchain transaction costs (gas fees), latency from consensus mechanisms, and the need for all participants to verify computations. The tradeoff is between the trust assumptions of centralized systems and the overhead of distributed consensus in decentralized alternatives.
Federated Averaging (FedAvg) is the foundational approach for horizontal federated learning, combining local stochastic gradient descent with periodic model averaging to achieve communication-efficient distributed training. The key innovation lies in allowing multiple local update steps before communication, achieving a 10-100x reduction in required communication rounds compared to synchronized stochastic gradient descent.
Algorithm Steps:
While federated learning avoids transmitting raw data, the model updates themselves, gradients or weight changes, leak substantial information about the underlying training data. Even though clients only share parameter updates rather than their datasets, these updates can be exploited through gradient-based attacks to infer sensitive properties or reconstruct training samples. This necessitates mechanisms for secure transmission and aggregation of updates, ensuring confidentiality throughout the federated learning pipeline.
The SMPAI protocol demonstrates a foundational approach for federated learning. The core mechanism relies on pairwise secret sharing: each pair of clients establishes shared randomness that masks their individual weights during transmission. The aggregator can compute the sum of masked values, but the random masks cancel out in aggregation, revealing only the desired weighted average.
Setup Phase: Every pair of clients and establishes common randomness using the Diffie-Hellman key agreement protocol. This shared secret is known only to the two participating clients. All operations are performed modulo some bound .
Masking and Transmission: At each training iteration, client masks its weight with the pairwise shared randomness. Specifically, adds all for and subtracts all for , sending to the server:
Aggregation: The server receives masked weights from all clients. When summing these values, the pairwise randomness cancels: each appears once as a positive term (from ) and once as a negative term (from ). The server computes:
The masked values reveal nothing about the individual weights to the server, as each is obscured by multiple random terms known only to pairs of clients.
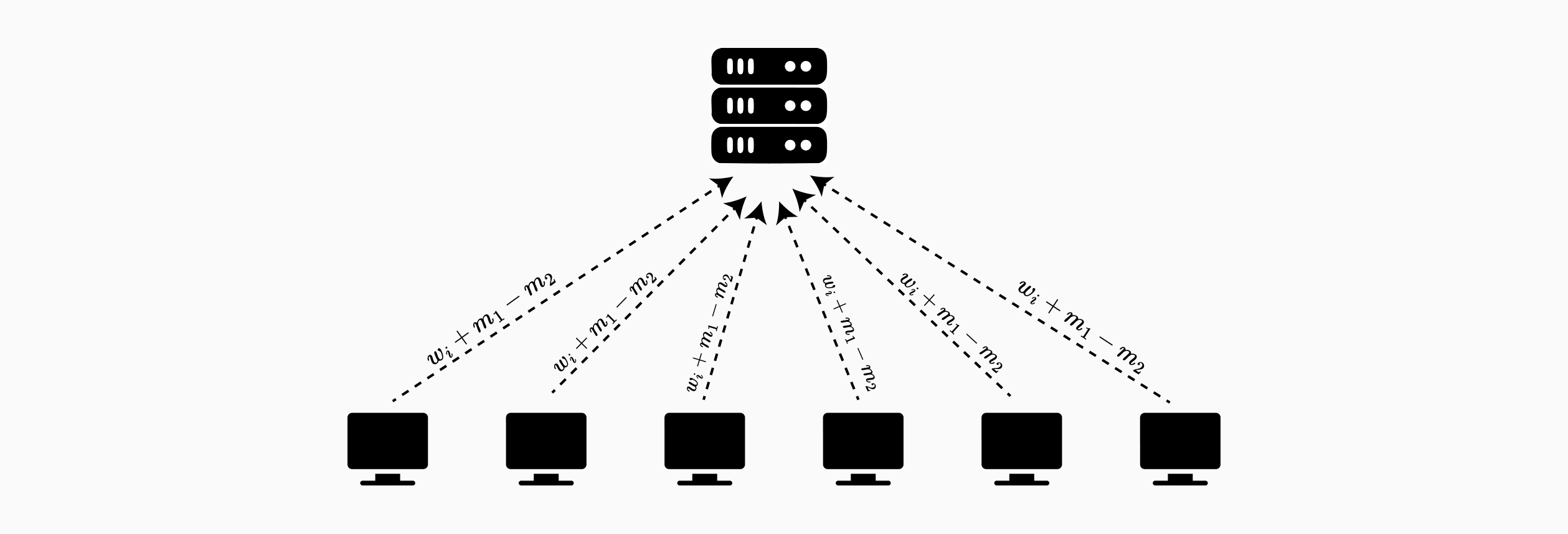
While this protocol hides individual weights from the server, the aggregated output itself can leak information. If clients collude, they can subtract their known contributions from the aggregate to recover the remaining client's weight. To prevent this, SMPAI incorporates differential privacy by having each client add calibrated noise to their weights before masking.
In the basic approach, each client independently samples noise from a Laplace distribution and adds it to their local weights. While this provides a baseline of security, the colluding participants can isolate the honest client's "noisy" weights; these adversaries can attempt to replicate the noise distribution (such as a Laplace distribution) and subtract it to guess the original sensitive input. However, SMPAI introduces a stronger mechanism: distributed noise generation. Rather than each client choosing their own noise, clients receive encrypted noise contributions from other participants. Each client receives two encrypted noise terms from every other client but selects only one of the two terms to add to their weights. This choice remains unknown to other parties.
For example, client receives encrypted noise pairs from and from . Client chooses one term from each pair (say and ) and computes:
This distributed mechanism ensures that even when parties collude, they cannot determine which noise terms the honest party selected, making it substantially harder to recover the honest party's original input compared to standard local differential privacy.
The SMPAI protocol demonstrates key tradeoffs in secure federated learning. The secret sharing mechanism eliminates single points of trust, no central server observes individual contributions. The distributed differential privacy provides protection even against extreme collusion where parties work together. However, these security guarantees come at a cost: communication overhead increases quadratically with the number of participants (each pair must establish shared randomness), and the added noise reduces model accuracy.
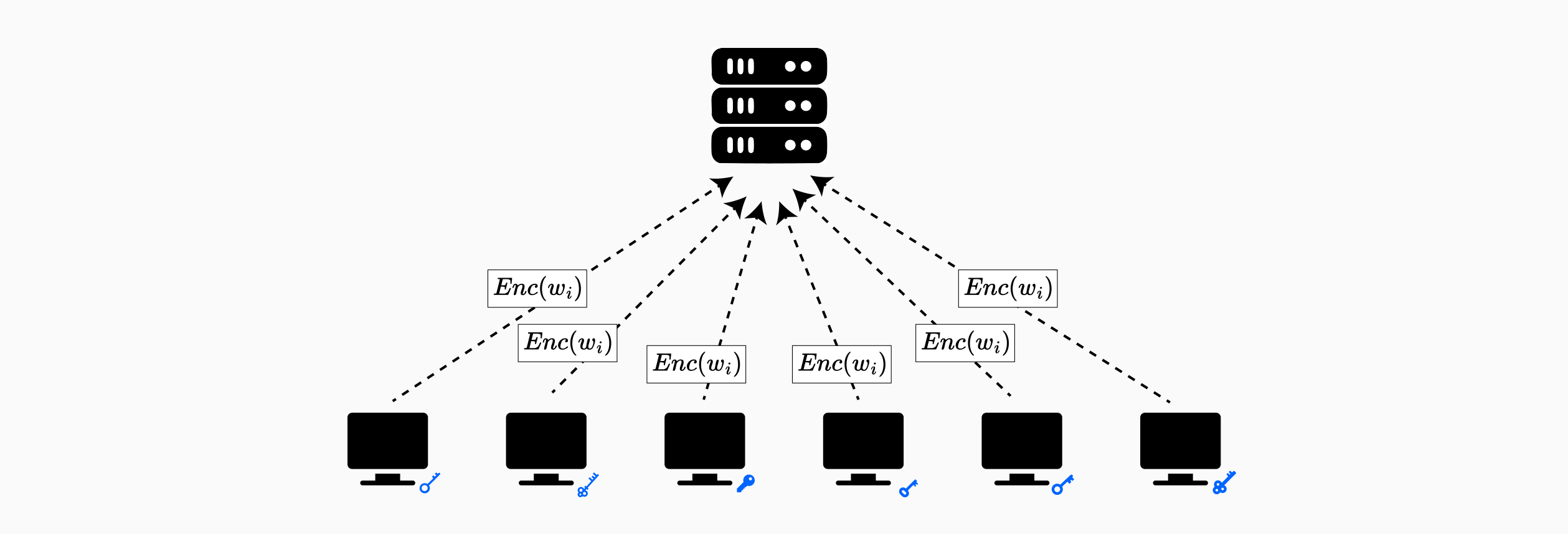
Homomorphic encryption enables computation on encrypted data without decryption, making it a natural fit for secure aggregation in federated learning. By encrypting model updates before transmission, clients can protect their gradients from a curious or compromised aggregator while still enabling the server to compute the sum required for model averaging.
BatchCrypt exemplifies the integration of homomorphic encryption into federated learning for cross-silo settings: scenarios where a small number of organizations, each holding substantial sensitive datasets, collaboratively train a model that only participants will access. Unlike cross-device federated learning with millions of mobile clients, cross-silo FL typically involves fewer than 100 parties (such as financial institutions, hospitals, or research organizations) that require strong privacy guarantees and can tolerate higher computational overhead.
The BatchCrypt protocol operates through the following phases:
After initialization, BatchCrypt treats all clients symmetrically, there is no distinction between the leader and other workers during training.
BatchCrypt employs the Paillier cryptosystem, a partially homomorphic encryption scheme that supports addition operations on ciphertexts. Specifically, given encryptions and , the Paillier scheme allows computation of without decrypting the individual messages. This additive property directly supports the gradient aggregation operation central to federated averaging.
However, a fundamental challenge arises: neural network gradients are floating-point values, while Paillier encryption operates on integers. To bridge this gap, BatchCrypt employs a quantization scheme that maps floating-point gradients to integer representations before encryption.
To further optimize performance, BatchCrypt encodes multiple quantized gradients into a single large integer before encryption, performing batch encryption rather than encrypting each gradient element individually. This batching strategy dramatically reduces the number of encryption operations and the resulting communication overhead.
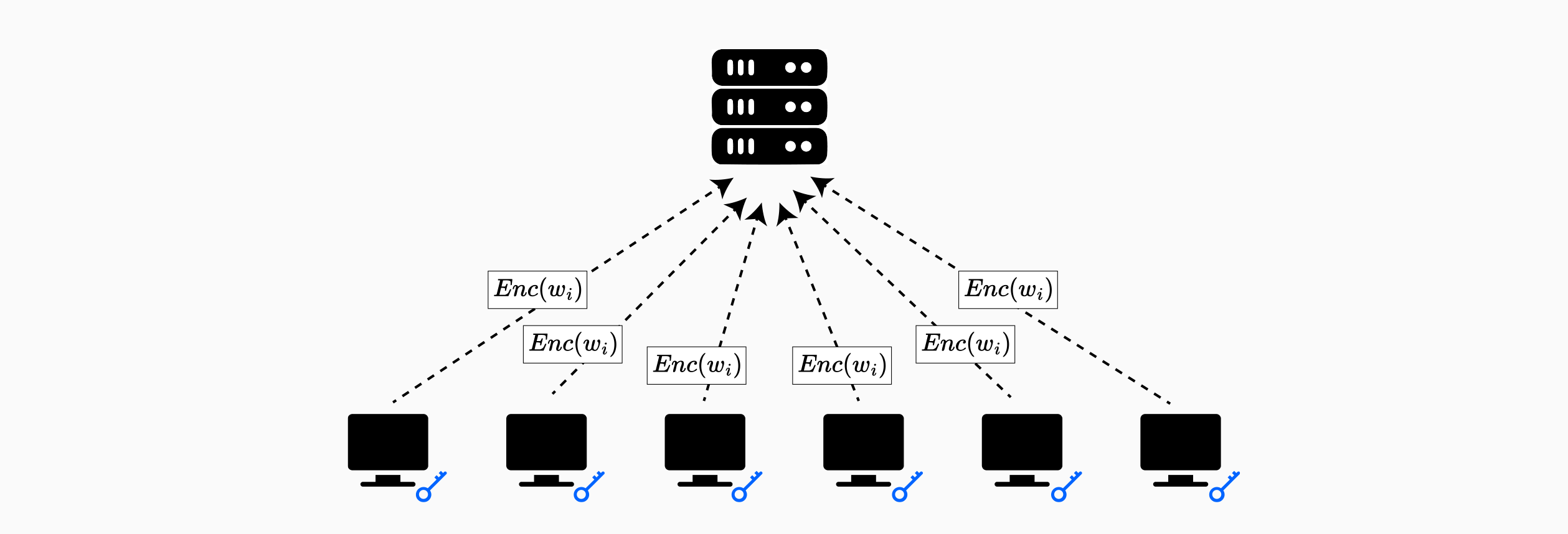
Despite its effectiveness, the BatchCrypt architecture reveals inherent security limitations in HE-based federated learning designs. Since all clients share the same encryption key pair, any single malicious or compromised participant can decrypt all gradient updates in the system. This single-key design eliminates confidentiality between clients while the aggregator cannot observe individual gradients, clients themselves can decrypt and inspect each other's contributions.
Moreover, homomorphic encryption operations remain computationally expensive even with BatchCrypt's optimizations. HE operations can dominate training time in federated learning systems, making the approach practical primarily for cross-silo settings where a small number of powerful organizations can afford the computational cost.
These limitations motivate exploration of alternative cryptographic approaches, such as secure multi-party computation and differential privacy, that offer different tradeoffs between security guarantees, computational overhead, and trust assumptions.
True secure multi-party computation (MPC) offers stronger security guarantees than the secret sharing approaches discussed previously by distributing trust across multiple computing parties rather than just masking values with pairwise randomness. MPC protocols enable multiple parties to jointly compute a function over their private inputs without any party learning anything beyond the final output. In federated learning, this means clients can aggregate their model updates without revealing individual contributions to anyone, including the aggregator.
The MPCFL protocol exemplifies the integration of MPC with federated learning using the Sharemind MPC framework. Unlike previous approaches where clients both provide inputs and perform computation, MPCFL introduces a clear architectural separation: input parties (clients with training data) and computing parties (entities that perform secure aggregation). The computing parties can be independent third parties or a subset of the clients themselves, but they operate separately from the data contribution process.
This separation provides flexibility in trust models. Organizations can outsource secure aggregation to trusted computing infrastructure without exposing their model updates, or they can designate some clients as computing parties to distribute trust within the federation itself.
The MPCFL protocol operates through the following workflow:
Local Training: Each of the clients trains their local model on their private dataset, computing weight updates for client using standard federated learning training procedures (e.g., stochastic gradient descent).
Secret Sharing: After local training, each client generates secret shares of their weight updates. The number of shares depends on the number of computing parties, for instance, with three computing parties, each weight update is split into three additive shares. Let denote the secret-shared representation of client 's weights distributed across all computing parties.
Share Distribution: Each client sends one share to each computing party. Importantly, no single computing party receives the complete weight update; each only holds a cryptographic share that reveals nothing about the original weights.
Secure Aggregation: The computing parties jointly execute MPC protocols to aggregate the shared weights without reconstructing individual client contributions. Using additive secret sharing, they compute the global aggregated weights:
where represents the weight coefficient for client , typically computed as: , with being the number of training samples held by client . This ensures clients with larger datasets contribute proportionally more to the global model. The operation is performed entirely on secret shares using MPC addition and multiplication protocols, producing a secret-shared result.
Result Reconstruction: After aggregation, the computing parties send their shares of back to the clients. Each client reconstructs the global model update by combining the shares they receive from all computing parties.
Model Update: Clients apply the reconstructed global update to their local models and proceed to the next training round.
Throughout this process, individual weight updates remain protected by the secret sharing scheme. The computing parties learn nothing about individual contributions, as they only process cryptographic shares. Even if some computing parties are compromised, the security guarantees hold as long as the threshold number of honest parties is maintained (e.g., in 3-party secret sharing, at least 2 parties must be honest).
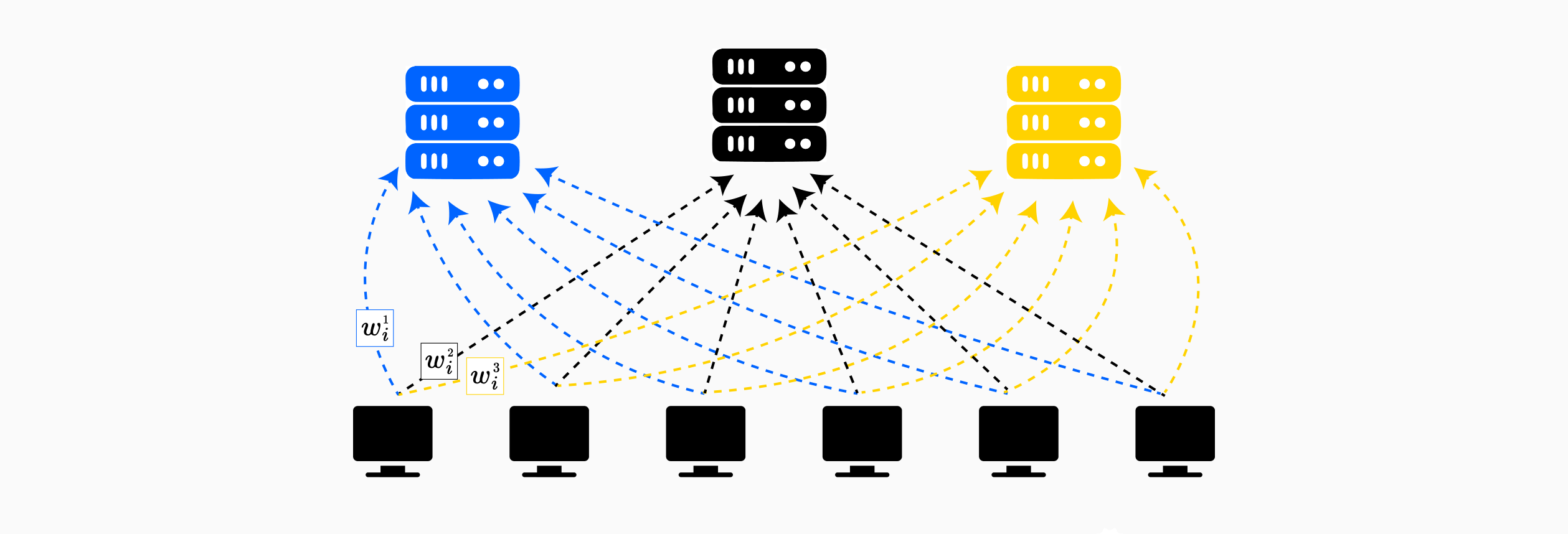
Multiparty homomorphic encryption (MHE) represents a significant advancement over single-key HE schemes by distributing the decryption capability across multiple parties while maintaining the ability to compute on encrypted data. This addresses a critical limitation in standard HE-based federated learning: the centralization of decryption power. Learn more about MHE schemes in this post.
The SPINDLE protocol exemplifies MHE integration into federated learning through a multiparty adaptation of the CKKS scheme. Unlike traditional homomorphic encryption where a single party holds the secret key, SPINDLE distributes the secret key across all data providers while maintaining a collective public key known to all participants.
Key Distribution: Each data provider holds a share of the secret key, generated through a distributed key generation protocol . The critical security property is that decryption requires collaboration from all parties, a ciphertext encrypted under can only be decrypted if every single data provider participates in the collective decryption protocol .
This architecture provides collusion resistance: as long as one honest data provider refuses to participate in decryption, the collectively encrypted model remains confidential. Even if every participant except one is malicious and shares their secret key shares, they cannot decrypt the model or training data.
SPINDLE integrates MHE into the cooperative stochastic gradient descent (CSGD) training workflow:
Initialization: Data providers collectively initialize cryptographic keys using and encrypt their initial model weights under the collective public key .
Local Training: Each data provider performs local iterations of gradient descent on its private dataset .
Homomorphic Aggregation (Combine): The encrypted local weight updates are aggregated using homomorphic addition as they ascend a tree structure. Each data provider combines its encrypted update with those of its children and forwards the result to its parent. The data provider at the root obtains .
Global Update (Reduce): The root data provider updates the encrypted global weights using weighted averaging.
Throughout this process, individual weight updates remain encrypted. No single party ever observes plaintext weights or gradients from other participants.
For prediction queries, SPINDLE uses a distributed key switching protocol that collectively re-encrypts prediction results from the collective public key to the querier's individual public key . This ensures:
The protocol preserves model confidentiality during inference while enabling practical private predictions.
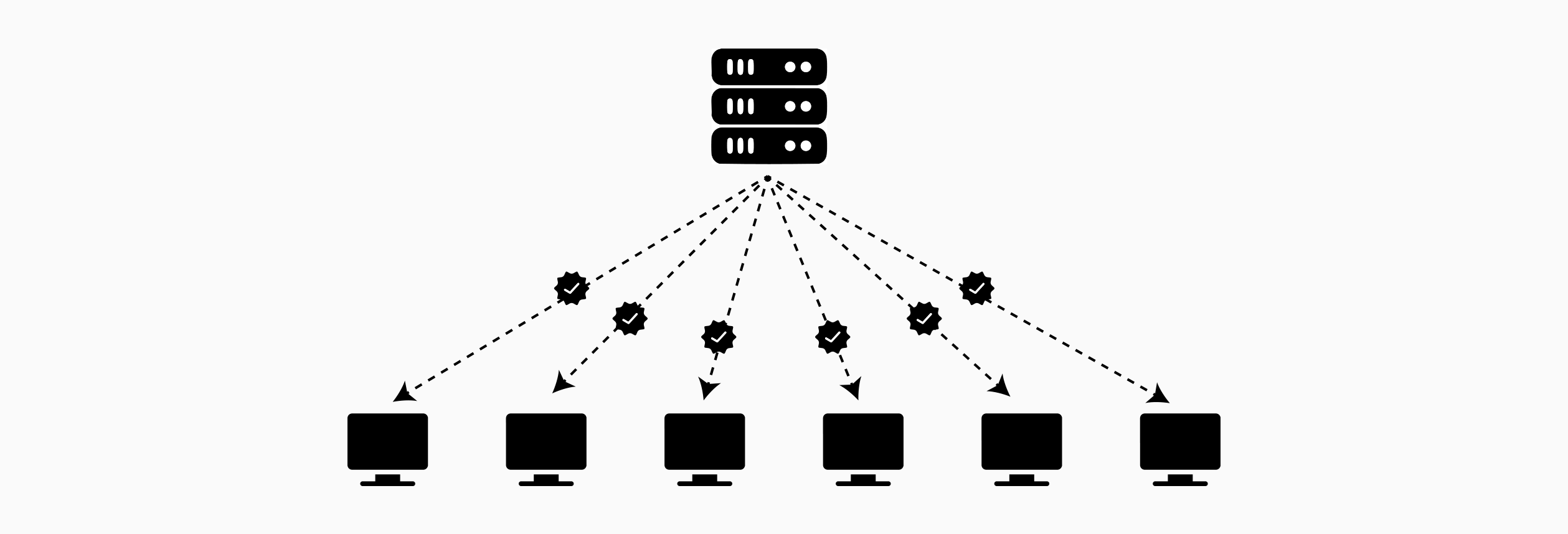
The cryptographic mechanisms explored thus far, homomorphic encryption, secure multi-party computation, and differential privacy, address confidentiality of data and model updates. However, they do not guarantee computational integrity: clients have no cryptographic assurance that the aggregator correctly executed the agreed-upon aggregation algorithm. A malicious or compromised server could selectively exclude certain clients, inject fabricated updates, or apply incorrect aggregation logic, all while maintaining encrypted communications. Zero-knowledge proofs provide verifiability without sacrificing privacy, enabling clients to cryptographically verify correct aggregation without learning individual contributions.
In standard federated learning, clients must trust that the aggregator:
A malicious aggregator could bias the global model toward specific outcomes by selectively weighting or excluding legitimate client updates. This threat is particularly acute in decentralized or cross-organizational federated learning where participants have competing interests.
The zkDFL protocol addresses the untrusted server scenario through zero-knowledge proofs integrated with blockchain-based verification. The system involves clients and one aggregation server, where clients cannot trust the server to aggregate honestly.
Setup Phase: Each client initializes with identical model parameters and registers a public blockchain address. All clients agree on the aggregation algorithm (FedAvg) and circuit specification that will be proven.
Client Selection: At each training round, the server selects out of clients to participate, balancing communication costs and model quality. Selected clients perform local training on their private datasets.
Local Training and Submission: Each selected client computes gradient updates through standard stochastic gradient descent on its local dataset. The client submits the gradient update to the server.
Server Aggregation: The server receives updates and computes their corresponding hashes . It performs FedAvg aggregation:
The critical innovation in zkDFL is the use of Groth16 SNARK to prove correct aggregation without revealing individual updates. The server constructs a zero-knowledge proof for an arithmetic circuit encoding the FedAvg algorithm.
Circuit Design: The Groth16 circuit takes as inputs:
The circuit proves two statements simultaneously:
The Groth16 proving system converts these arithmetic constraints into a Quadratic Arithmetic Program (QAP) and generates a succinct proof .
zkDFL employs two complementary smart contracts deployed on a blockchain to establish trust:
Contract 1 - Groth16 Verifier: This contract verifies the zero-knowledge proof submitted by the server. It checks that the server correctly aggregated some updates whose hashes match the public inputs. However, this alone does not guarantee that the server used the specific updates from all participating clients.
Contract 2 - Hash Registry: Each client independently submits its hash to this registry contract. When the -th client submits their hash, the contract computes:
This represents the sum of hashes that clients actually submitted.
Verification Condition: The server's proof includes a public output representing the sum of hashes it used in aggregation. Verification succeeds if and only if:
This equality guarantees that the server used exactly the set of updates from participating clients, with no additions, deletions, or substitutions.
While zkDFL addresses server untrustworthiness, Federify tackles the complementary problem: untrusted clients in a decentralized setting. Rather than verifying that a central server aggregated correctly, Federify ensures that clients computed their local models correctly before submitting them for aggregation.
Decentralized Architecture: Federify eliminates the central aggregator entirely, replacing it with a smart contract deployed on a public blockchain. The framework involves two types of participants: Data Owners (DOs) who hold training data and contribute local model updates, and Model Owners (MOs) who sponsor training by providing capital and participating in threshold decryption.
Registration Phase: Each Model Owner registers with the smart contract by submitting:
The smart contract aggregates all local public keys to form a global public key for the threshold ElGamal encryption scheme . This global public key enables encryption by any party, but decryption requires collaboration from at least out of Model Owners.
Federify's security relies on distributing decryption capability across multiple parties through a -threshold ElGamal cryptosystem. Each Model Owner generates a secret key and corresponding public key (where is a base point on an elliptic curve). The private key is never held by one person; instead, each MO shares their secret key using polynomial secret sharing. The threshold property ensures that at least Model Owners must participate to decrypt, preventing any single party or minority coalition from accessing the plaintext model.
Data Owners train Gaussian Naive Bayes classifiers on their local data. For a batch of samples with features, a DO computes mean and variance for each feature . Before submitting, the DO encrypts these parameters:
The critical verification step uses two zkSNARK circuits:
Circuit 1 - ValidateModel: Verifies that model parameters were correctly computed from the training data
Circuit 2 - ValidateEncryption: Verifies that encryption used the correct global public key
The Data Owner submits a transaction to the smart contract, which verifies the proof before accepting the update. Upon verification, the smart contract homomorphically aggregates the encrypted parameters. This aggregation leverages ElGamal's additive homomorphic property: .
Once Data Owners have submitted updates for all classes, Model Owners collaboratively decrypt the aggregated model. Each performs partial decryption using their secret key share , where represents the encrypted aggregated parameters. To prevent malicious MOs from submitting incorrect partial decryptions, each must provide a zkSNARK proof (ValidateDecryption) proving:
The smart contract verifies each partial decryption proof. Once valid partial decryptions are submitted, the plaintext global model can be recovered:
The threshold property ensures robustness: even if some MOs refuse to participate, any honest MOs can recover missing contributions using their secret shares.
Federated learning enables collaborative model training without centralizing sensitive data, but naive implementations remain vulnerable to privacy and integrity attacks. This article has examined cryptographic mechanisms that address three critical requirements: confidentiality of model updates, robustness against malicious participants, and verifiability of computations.
Secret sharing and homomorphic encryption provide confidentiality during aggregation, with tradeoffs between computational overhead and security guarantees. Multi-party computation distributes trust across multiple parties, eliminating single points of failure. Differential privacy adds formal privacy guarantees through calibrated noise, trading accuracy for protection against inference attacks. Zero-knowledge proofs enable verifiable computation, allowing participants to cryptographically verify correct aggregation or local training without compromising privacy.
The choice among these approaches depends on deployment context. Cross-device federated learning with millions of clients demands lightweight protocols, while cross-silo settings among powerful organizations can tolerate heavier cryptographic operations. Decentralized architectures benefit from blockchain-based verification.
These cryptographic mechanisms are not merely theoretical constructs, they have transitioned from academic research to production deployment. Several frameworks now provide implementations of secure federated learning techniques. NVIDIA FLARE offers homomorphic encryption and differential privacy capabilities for healthcare and financial applications. TensorFlow Federated integrates secure aggregation protocols into Google's machine learning ecosystem. Flower provides a framework-agnostic platform with support for differential privacy and secure aggregation via masking. FATE implements multiple cryptographic protocols including homomorphic encryption and secure multi-party computation for enterprise federated learning. These production-ready frameworks demonstrate that secure federated learning has moved beyond proof-of-concept, with organizations across healthcare, finance, and technology sectors actively deploying privacy-preserving collaborative machine learning systems at scale.

