
AI
Jun 15, 2026
Understanding Differential Privacy: Part 2
A hands-on guide to DP-SGD: how it works, how VaultGemma uses it at LLM scale, and what private vs non-private training actually costs on ...
AI
Jun 5, 2026

Every useful dataset is also a liability. The same medical records, location traces, and behavioral logs that train better diagnostic models, route ambulances faster, and personalize the products we use are also documents people did not necessarily consent to making public. For most of the last two decades, the industry response to this tension has been a patchwork of fixes: strip the names, blur the timestamps, replace identifiers with hashes, release only aggregates. A line of attacks has made it clear that these fixes do not hold up.
Differential privacy is the field's response to this failure. The guarantee it offers is mathematical, not heuristic. Loosely, an algorithm is differentially private if its output distribution barely changes when any single individual's record is added to or removed from the input. Whatever an attacker learns from the output, they would have learned almost the same thing had you never been in the dataset at all.
In this article we start with the attacks that motivate DP in the first place, then state the formal definition and unpack what its parameters actually mean. From there we look at trust models and deployment settings, the standard mechanisms and their analysis and the accounting machinery that keeps long training runs tractable.
Traditional defenses have repeatedly proven inadequate against adversaries with serious computational tools and access to auxiliary datasets. The cleanest way to see why is to look at the attacks that defeat them.
A linkage attack works by joining a "de-identified" dataset against an external source that shares some attributes with it. Even when names are stripped, the remaining fields are often unique enough in combination to pin a row to a person. Sweeney's 1997 attack re-identified medical records by joining them against voter registration data, showing that the combination of ZIP code, birth date, and gender was enough to re-link supposedly anonymous records to individuals. The same template defeated the Netflix Prize release: Narayanan and Shmatikov showed that the released ratings data could be linked to IMDb to recover the viewing histories of specific users. Linkage attacks are the proof that "anonymization" is not a property you can verify by inspecting a dataset on its own, it depends on what other data happens to exist in the world.
Reconstruction attacks, on the other hand, try to recover the rows themselves from a series of aggregate releases. The foundational result is due to Dinur and Nissim, who proved that releasing too many highly accurate statistics about a dataset allows an adversary to reconstruct a large portion of the original records, saying that overly accurate answers to too many queries can destroy privacy. This is not a theoretical worry. Working with the published statistical summaries from the 2010 U.S. Census, researchers at the Census Bureau were able to reconstruct individual-level records. This result directly motivated the Bureau's decision to adopt DP for subsequent releases.
Differencing attacks weaponize the gap between two aggregate queries that overlap in everything except one person. If a system reports the average salary of "employees in department X" and "employees in department X excluding Alice," subtracting one from the other gives Alice's salary directly, regardless of how many people are in the average. A version of this attack surfaced on Facebook's advertising platform: by crafting highly specific target audiences and comparing the resulting ad reach statistics, an attacker could infer sensitive traits, including sexual orientation and medical conditions, about individual users.
Membership inference asks a narrower but often equally damaging question: was this specific person's record in the dataset? In medical or genomic settings, the answer alone is sensitive, confirming that someone was in a cohort of HIV patients or rare-disease participants is already a disclosure. Shokri et al. showed that trained models leak membership, allowing an adversary with only query access to the model to tell, with non-trivial accuracy, whether a particular record had been in the training set.
Rather than asking whether a dataset is "anonymous," DP asks a question about an algorithm: if you ran it on a dataset that differs by one person, how different would the output look? If the answer is almost the same, with high probability, the algorithm is private.
The basic unit of analysis is a pair of neighboring datasets, that is two datasets that are identical except for the data of a single individual. We write to mean that can be obtained from by adding or removing one record. This is the add-or-remove criterion. Two alternative conventions appear in the literature. The replace-one criterion says that is obtained from by replacing one record with a different record; the zero-out criterion replaces a record with a designated "zero" value rather than removing it. The add-or-remove and zero-out variants give semantically equivalent guarantees with respect to , while replace-one is roughly twice as strong, since a replacement is effectively an add plus a remove.
A related choice is what counts as a "record" in the first place. This is the unit of privacy. Example-level (or sample-level) DP treats each row of the dataset as the protected unit, while user-level DP protects all of the data contributed by a single user, even when one user contributes many rows. The difference matters whenever individuals contribute repeatedly like a user with months of typing logs or a patient with many medical records, because example-level guarantees can lessen when one person's records are correlated across many rows.
With neighbors in hand, the standard definition is short. A randomized mechanism , mapping datasets to some output space , satisfies pure -DP if, for every pair of neighboring datasets and every measurable set of outputs ,
In many practical settings, especially in machine learning, pure -DP is too restrictive, the standard relaxation is approximate -DP:
Setting recovers pure -DP. Allowing tolerates a small probability that the multiplicative bound fails to hold.
The parameter controls how much an adversary's inference about any one record can shift when that record is added or removed. A smaller means stronger privacy, so the output is less sensitive to any individual's data, while a larger means weaker guarantees. At the output is statistically independent of the input, which makes it useless. There is no single "right" value; for common statistical queries is typically chosen below 1, whereas in deep learning settings it is often relaxed to around .
The parameter needs extra care because it allows a small probability of a complete privacy failure. Recall that -DP requires that for neighboring datasets and and every possible output event ,
Now consider a deliberately terrible mechanism: it takes a dataset of people, chooses one person uniformly at random, and releases that person’s full record with no noise. Fix one individual, say Alice, and let be the event that the mechanism outputs Alice’s record. If Alice is in the dataset , then
But in the neighboring dataset , where Alice’s record has been removed, the mechanism cannot output her record at all, so
Plugging this into the DP definition gives
so
This means that even an obviously unsafe mechanism can satisfy -DP if is at least about . The reason is that the probability of exposing any fixed individual is hidden inside the allowed failure probability .
This is why should be much smaller than . If were on the order of , then in a dataset with people, the guarantee could still allow roughly one catastrophic disclosure in expectation. More generally, if each record has failure probability about , then the expected number of failures across the dataset is about . So reporting an guarantee without saying what is or choosing is much weaker than it may sound.
The formal definition of DP says nothing about who runs the mechanism. In practice that matters a great deal, because privacy guarantees on a final output do not protect users from whoever holds the raw data before noise is added. Trust models are the standard way to organize this question, they specify, for each part of the pipeline, what an adversary is assumed to see and which failures the protocol is supposed to survive.
Central DP is the classical setting and the easiest to reason about. A trusted curator (or a trusted aggregator) collects raw, unperturbed data from users, applies a DP mechanism, and releases outputs that satisfy formal DP guarantees. Users must trust this aggregator both to safeguard the raw data and to implement the mechanism correctly. The adversary is assumed to observe only the final output. Because the curator has access to unperturbed data, only a small amount of noise is needed, which is why central DP typically achieves the highest utility of any setting. The standard applications that fit this profile are centralized analytics and ML pipelines, and research analyses under strong governance, including healthcare studies that protect patient information.
The weakness of central DP is exactly what makes it convenient: it concentrates risk on the curator. If the curator is breached, malicious, or compelled to hand over data, DP on the final output is no comfort to people whose raw records have already been exfiltrated. A 2018 Google+ leak affected hundreds of thousands of users, a separate Google+ API bug later that year exposed the data of 52.5 million users, and a 2019 Facebook breach exposed IDs, phone numbers, and names of hundreds of millions. Even reputable, well-resourced curators are at risk.
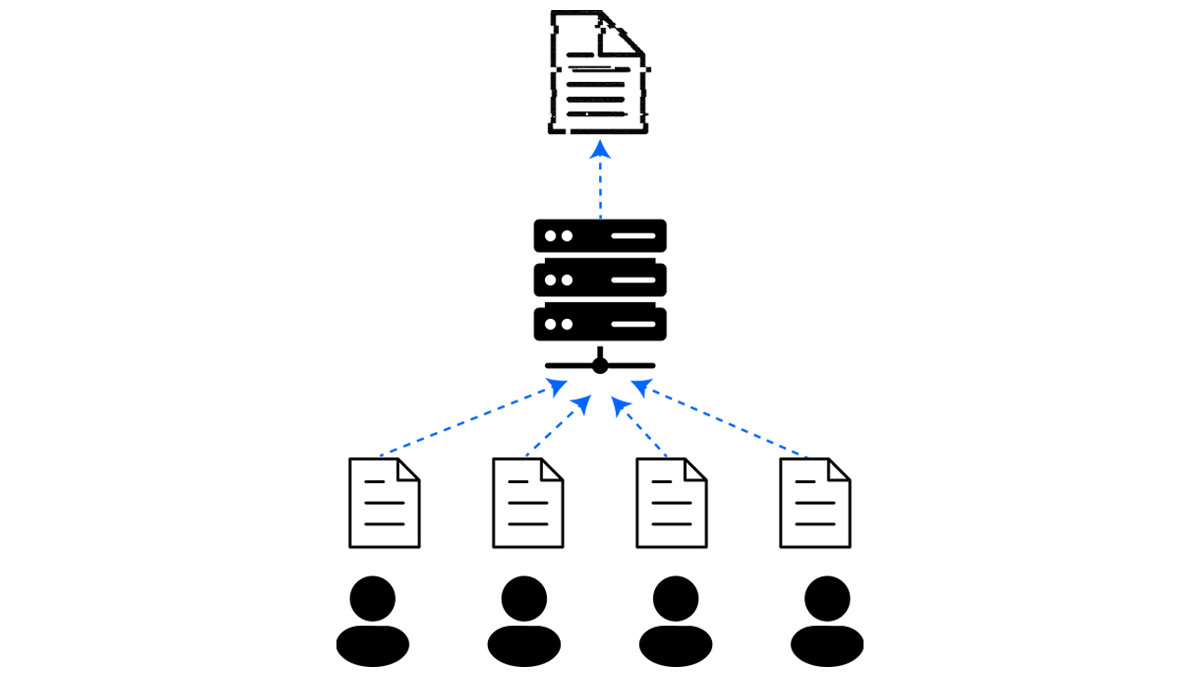
Local DP eliminates the trusted curator by moving the noise onto the user's device. Each user applies a predefined randomized mechanism to perturb their own data before anything is sent to a server. As a result, the server never sees the raw values, and privacy holds regardless of the aggregator's behaviour.
The price is utility. Because every user adds noise independently, local DP typically requires much larger per-user noise than the central setting, which translates to lower accuracy. Local DP is best suited for very large user bases performing simple aggregate analyses like Apple's iOS telemetry for emoji usage and typing behaviour.
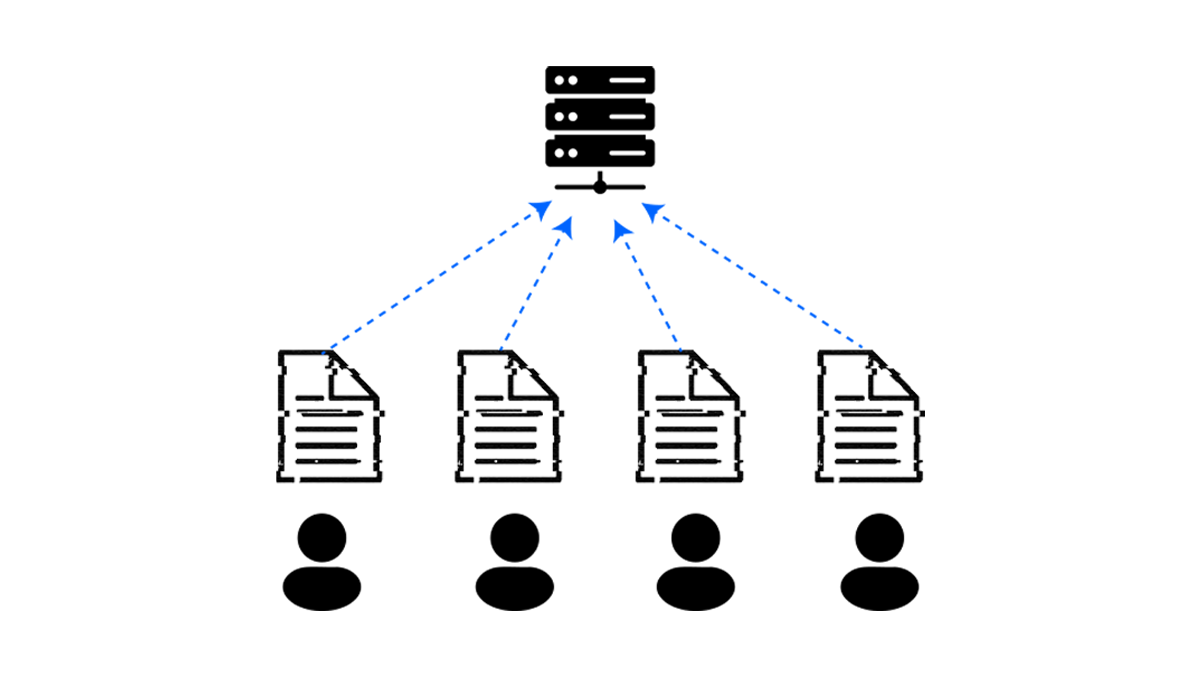
Shuffle DP introduces a semi-trusted shuffler between users and the aggregator: each user sends their data through the shuffler, which removes any user identifiers and randomly permutes the reports before they reach the aggregator. The aggregator then adds a small amount of noise to the shuffled aggregate. Deployments include federated learning with secure aggregation and sparse location heatmaps generated from many users' reports without any central trusted curator.
The catch is the trust assumption on the shuffler. If the shuffler colludes with the aggregator the model effectively collapses, so it is usually implemented with cryptographic protections (secure aggregation, mixnets) ensuring that no single party can both see identifiers and read message contents.
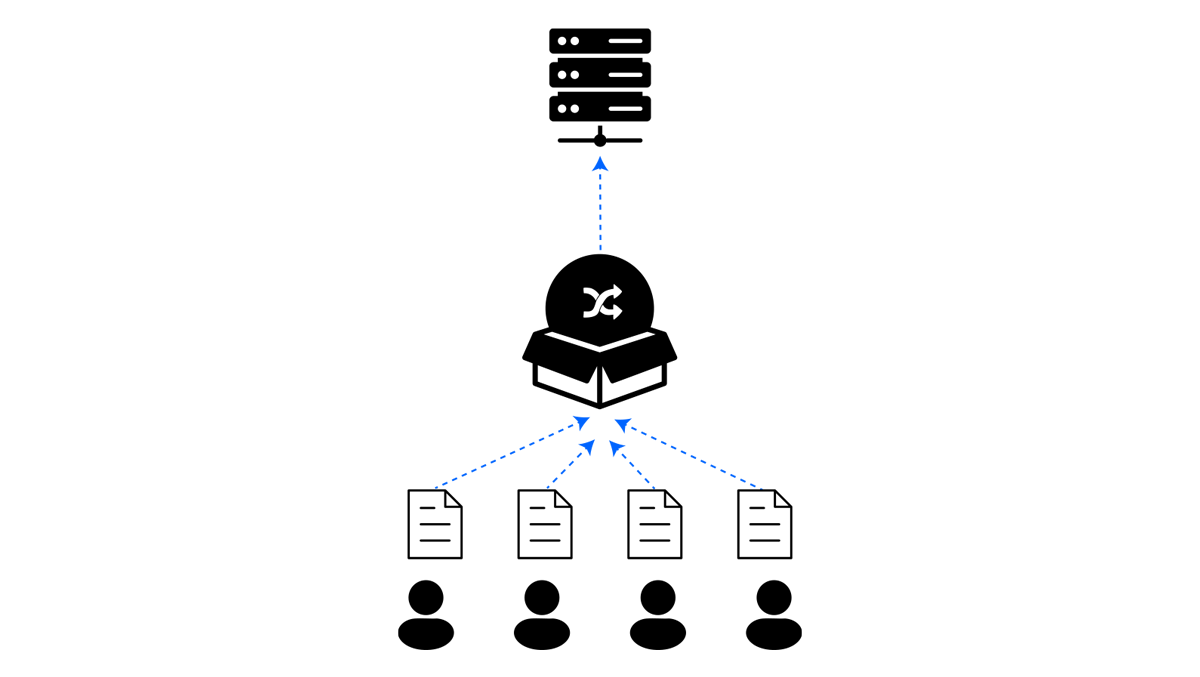
Pan-privacy is conceptually distinct from the three settings above, it introduces the notion of time. Users contribute their data to the server sequentially; once collection is complete, the output is released. The trust model is time-sensitive meaning users trust the server at the moment they hand over their data, but not necessarily after. A pan-private algorithm guarantees that if the server is later compromised, the data already in the server stays private. In practice, pan-privacy is rarely deployed standalone. It is best thought of as a property layered on top of a central or distributed system.
Trust models define who is trusted and who is adversarial. Deployment settings define the circumstances: where the data is created, where it can move, who is allowed to process it, and what infrastructure already exists.
If the data is generated on millions of phones, the system may need client-side or federated methods. If the data already lives in a central statistical agency or hospital system, a trusted-curator model may be realistic. If no single party is allowed to see the full dataset, then distributed protocols become necessary.
The centralized setting is the one most DP tooling is designed for. A single server (or cluster) holds the dataset, runs the analysis or training pipeline, and produces a private output.
The curator has access to unperturbed data, so noise can be calibrated once at the aggregate level. The implementations are also relatively well-developed, with libraries like TensorFlow Privacy and Opacus.
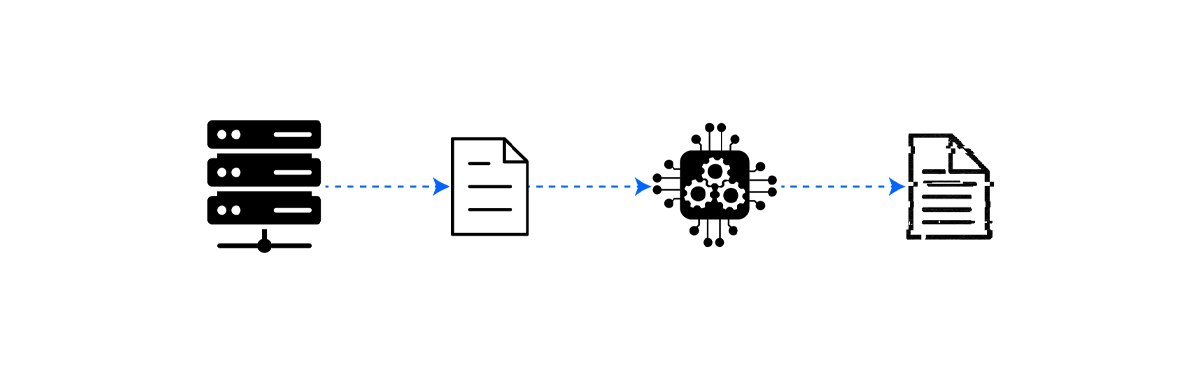
When data cannot be centralized, the noise has to move to the device. A client-side deployment runs a small randomizer on each user's device, applies it to a single data point (or a small per-user payload), and transmits only the perturbed report. The server's job is reduced to aggregation. Examples of this setting are Google's RAPPOR, used for collecting Chrome browser-configuration data via randomized response, and Apple's iOS telemetry pipeline, which uses local DP for emoji usage, typing behaviour, and Safari domain popularity measurements.
The third architecture is federated: a coordinating server orchestrates training across many participants that keep their data local such as phones, hospitals and banks. Each participant computes updates (typically gradients) on its own data and sends those updates to the server, which aggregates them into a global model. The data itself never moves.
Federated learning becomes a DP system when noise is added to the updates: each device clips and noises its own gradient contribution, the server sums the contributions without seeing individual updates, and the privacy budget is tracked across rounds.
The engineering complexity is significantly higher than in either of the other two settings. Federated systems have to handle heterogeneous data distributions across participants, devices that drop out mid-round, asynchronous availability, and communication-bandwidth constraints. Frameworks like Flower and TensorFlow Federated have made these systems much more tractable to build than they were five years ago, but federated DP remains the most operationally demanding of the three architectures. You can read more about Federated Learning in our previous post.
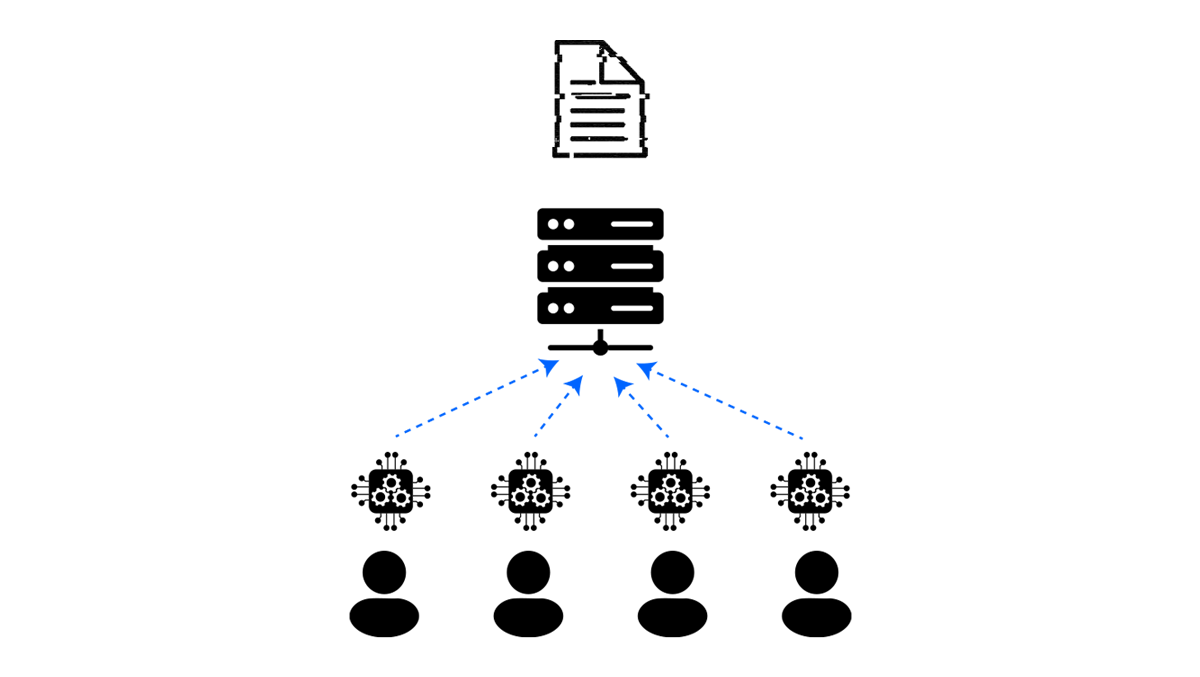
The trust model fixes who is allowed to see what, and the deployment setting fixes what the system physically looks like. Inside that frame, there is one more decision with large consequences for utility and accounting: at which point in the pipeline does the noise actually enter?
Input perturbation adds noise to the data itself, before any training. After that, every downstream computation inherits the guarantee for free. This is what powers DP synthetic data releases and what makes local DP work: each user randomizes their record, and anything the server does with it is private by default.
The win is reusability. One private dataset can train many models, support hyperparameter sweeps, and feed comparisons without spending any more budget. It also gives the strongest guarantees of the three options.
The cost is utility. Noise has to be calibrated for the worst-case downstream use, not the actual one, which usually means more noise than any single task would need. Local-DP training and DP synthetic data both pay heavily for this, which is why input-level DP is often the hardest to deploy well.
Training-time perturbation modifies the algorithm rather than the data. The curator holds the dataset privately, the training procedure injects noise during optimization, and the released model is the differentially private object. Every prediction the model later produces is also private.
The advantage over input perturbation is utility. Because the optimizer sees clean data during training, noise can be calibrated against what the optimization actually needs to tolerate, not against a worst-case downstream query. The advantage over output perturbation is scope: the model itself is private, so once it is trained it can be released, served, or shared.
The costs arise from hyperparameter sensitivity, the computational overhead of per-example gradient computation, and the need for careful accounting across long training runs.
Output perturbation leaves the data and the algorithm alone and adds noise at the end of the pipeline, when the answer is returned. The canonical example is a privacy-preserving prediction API: the model itself isn't released, and each query is perturbed enough that no single prediction reveals much about any one training example.
This works best when the number of queries is tightly bounded. For a system that releases a handful of aggregate statistics from a frozen dataset, perturbing the outputs directly is simple and easy to account for.
The catch is that the budget scales with queries. Every output draws from the same finite , so a system answering many queries eventually runs out. For ML specifically, training-time DP usually gives a better privacy-accuracy trade-off, especially with large inference budgets or large training sets and it protects the model parameters too, which output perturbation doesn't.
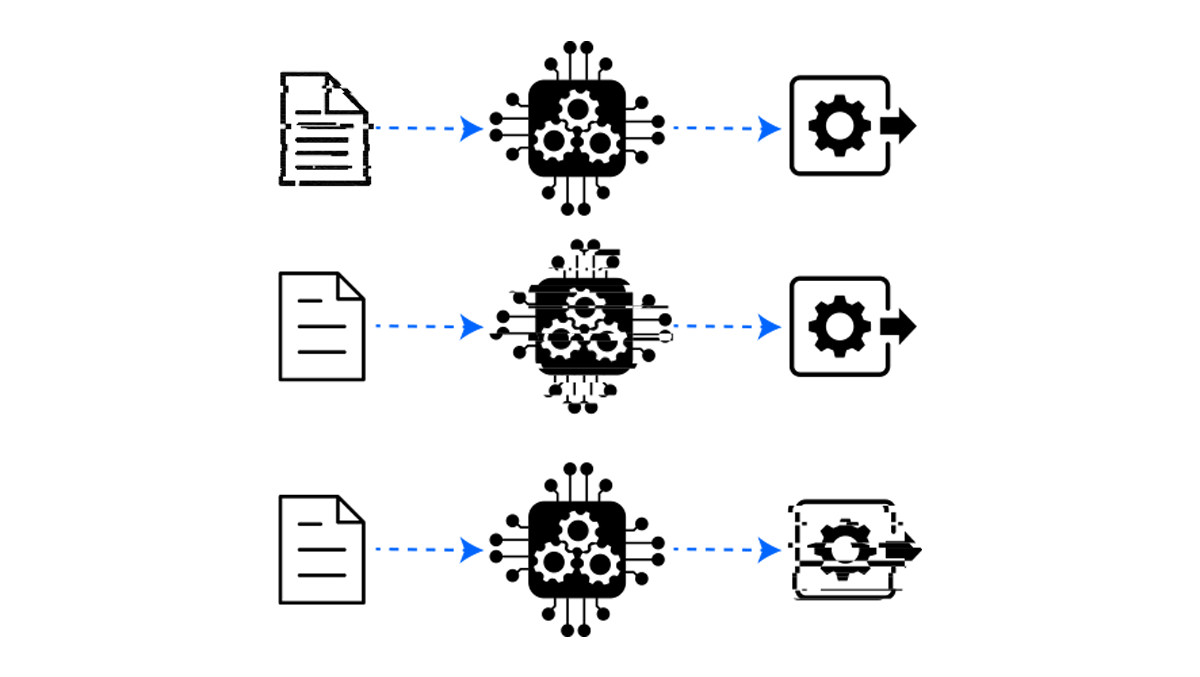
Every DP system needs a concrete mechanism: figure out how much one person's contribution can shift the output (sensitivity), pick a noise distribution whose spread covers that shift, and verify that the resulting algorithm fits one of the DP definitions.
Sensitivity is the bridge between a function and the amount of noise required to make it private. It measures the worst-case change a single person's data can produce in the function's output. Formally, for a query function and the set of all neighboring dataset pairs, the global -sensitivity of is
where is the -norm. Two specializations matter most: -sensitivity (used by the Laplace mechanism) and -sensitivity (used by the Gaussian mechanism).
The amount of noise a DP mechanism must add is directly proportional to . Queries with higher sensitivity require more noise to mask the influence of any one individual. Here are some examples for better intuition:
In practice, sensitivity is often unbounded or hard to estimate. The standard fix is clipping: bound the per-record contribution (or in ML, the per-example gradient) to a fixed norm , which forces by construction. Clipping introduces a bias–variance trade-off: too tight a clip distorts the function being computed, too loose a clip requires too much noise.
The Laplace mechanism is the simplest DP building block. It adds noise drawn from the Laplace distribution. The Laplace distribution centered at zero with scale parameter has density
variance , and exponential tails. We write for this distribution.
For a query , the Laplace mechanism adds independent noise to each coordinate:
and the resulting mechanism satisfies pure -DP.
A worked example: suppose a security analyst wants to release the count of log entries matching a particular malware signature. Adding or removing one entry changes the count by at most one, so , and the mechanism returns
At , the noise has standard deviation , so the published count is usually within a handful of the true value yet no adversary can determine from the output whether any specific log entry was included. The Laplace mechanism is the default tool for releasing counts, sums, and averages under pure -DP.
The Gaussian mechanism is the workhorse for -DP. The structure mirrors Laplace, but the noise is Gaussian and the calibration is to -sensitivity rather than .
For , the Gaussian mechanism is
with
This noise scale guarantees that the mechanism satisfies -DP.
Why prefer Gaussian over Laplace? In low dimensions, often you don't. In high dimensions, Gaussian has practical advantages. -sensitivity is typically much smaller than -sensitivity: for a -dimensional vector each of whose entries can change by at most one, grows as while grows only as which means less total noise is required.
A concrete example: a hospital publishes the average BMI of 100 individuals, with BMI bounded in the physiological range . The maximum any one person can shift the average is , so . To achieve ,
About 99.7% of Gaussian draws fall within , so the published average lies within roughly that range of the truth. It's wide enough to hide any single contribution, narrow enough to remain useful in practice.
Laplace and Gaussian assume a trusted curator who already has the data. Randomized response is the canonical mechanism for local DP. The user randomizes their own answer before sending anything to anyone.
The classical version handles a sensitive yes/no question. Each respondent flips a fair coin, answers truthfully if it lands heads, and otherwise flips a second coin to choose "yes" or "no" at random. The probabilities work out as:
The privacy loss on observing a "yes" is therefore , and on observing a "no" it is . The maximum across all outputs defines , so the classical randomized response mechanism satisfies -local DP with . The analyst can still estimate the population proportion accurately: knowing the randomization rule, they can subtract off the share of responses that are random and recover an unbiased estimate of the true rate.
Standard DP applies the same budget to every individual. Personalized DP (PDP) loosens this by assigning each user their own , so users with stronger privacy preferences or with more sensitive data get tighter guarantees. This requires modifying the underlying mechanism to enforce the per-user budgets.
Two related notions sit nearby and are sometimes used interchangeably with PDP, but should be distinguished. Heterogeneous DP assigns different privacy levels by system-level factors like data sensitivity, model roles, or organizational policies, rather than by explicit user preference; it has been applied in federated learning settings where participants come with different governance requirements. Sensitive privacy adapts to each record's "outlierness," providing weaker protection for rare records and stronger protection for typical ones. This is useful in tasks like anomaly detection, where strict uniform DP is effectively incompatible with the task.
Training a model takes thousands of rounds, and each round is another release on the same data. The training algorithm itself comes in Part 2, but the accounting machinery is worth setting up now.
This section is about tracking how privacy loss adds up across rounds. The naive answer is to sum the per-round 's. This works but gets useless fast once the number of rounds is large. Tighter accounting is what keeps the final guarantee meaningful.
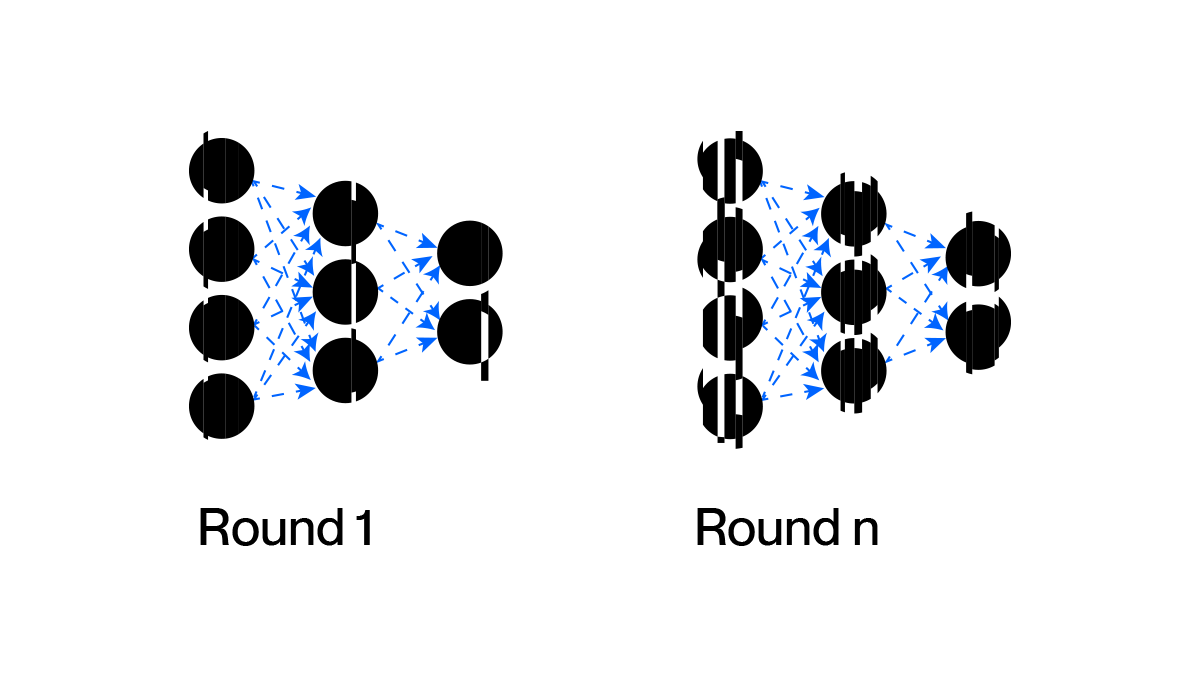
The starting point is sequential composition. If you release the outputs of mechanisms that each satisfy -DP, the combined release satisfies -DP. This is what 'privacy budget' actually means: every release spends some, and the totals accumulate by addition.
Consider a thought experiment: a training run of gradient steps, each with a per-step of which would already be a tight per-step bound. Naive composition reports a final , a guarantee so loose it conveys essentially nothing about the actual privacy of the trained model. The mechanism leaks much less than this; the bound is just bad.
The intuition for why sequential composition is loose: it adds up the worst case over every step, treating every step's privacy loss as if it were maximal and all pulling in the same direction. Tighter accounting comes from refusing to take the worst case quite so literally.
The first real refinement is advanced composition. For mechanisms each satisfying -DP, the composition satisfies -DP for any , where
For small , the second term is negligible and the bound simplifies to
The key change is the scaling: the dominant term grows as the square root of the number of compositions, not linearly. The price is a small extra . Intuitively, per-step privacy losses behave like noisy random variables that partially cancel rather than always conspiring; their sum has -style fluctuations, not -style.
Replaying our thought experiment with advanced composition and :
The same algorithm now reports an around 6 instead of 100, which is better, but still too loose for many real training runs. For long training runs in particular, advanced composition remains overly conservative, which is exactly the gap that the moments accountant was designed to close.
The big jump came with the moments accountant. The idea is to stop bounding the worst-case privacy loss and start tracking its statistical behaviour directly.
For each step, define the privacy loss random variable
where is drawn from . Sequential composition bounds the supremum of this random variable. The moments accountant instead tracks its log moments:
For the subsampled Gaussian mechanism with sampling rate (batch size over dataset size) and noise multiplier , the derived bound is
Three things make this powerful. First, log moments add cleanly under composition: after steps, the cumulative log moment is bounded by . Second, the bound scales as in the sampling rate, which captures the privacy amplification from subsampling (the next subsection). Third, the cumulative log moment converts back into a final via a tail bound,
which is then optimized over the moment order to give the tightest possible pair.
The improvement over advanced composition is order-of-magnitude in real scenarios. Consider training with sampling rate , noise multiplier , and . Each epoch runs steps. At epochs (10,000 steps), advanced composition reports while the moments accountant reports . At epochs (40,000 steps), advanced composition gives and the moments accountant gives . Same algorithm, same noise, much tighter story about what it leaks.
A separate phenomenon, tied to everything above, is privacy amplification by subsampling. The intuition is short. Suppose a base mechanism satisfies -DP when applied to a fixed dataset. Now consider the subsampled mechanism that first draws each record independently with probability (Poisson subsampling), then applies to the subsample. Any particular record appears in the subsample only with probability , so an adversary observing 's output can't tell whether the record was excluded by the subsampler or simply absent from the dataset. The amplified guarantee is approximately
which for small is close to -DP. A per-step of at full batch becomes a per-step of around when the sampling rate is , that's roughly a hundredfold tightening.
Differential privacy didn't replace ad-hoc anonymization because it looked nicer on paper. It replaced it because every other approach failed. The four attacks at the start of this article aren't exotic edge cases. They're what happens when you release data without a formal model of what an adversary can do with it. DP starts from the opposite assumption: the adversary is allowed to be clever, well-resourced, and to have arbitrary side information but the guarantee has to hold anyway. Much of the framing and many of the examples in this article draw on "A Comprehensive Guide to Differential Privacy: From Theory to User Expectations", which we recommend if you want a deeper survey of the field.
Part 2 picks up where the accounting section leaves off. We'll work through DP-SGD, the training algorithm that turns all of this machinery into a private model, and then put it to use. The plan is to train a simple model on the same dataset twice, once normally and once with DP-SGD using one of the libraries mentioned above, and look at what the privacy-utility trade-off actually costs in practice. How big is the accuracy gap at different values of . How clipping and noise interact during real training. What the reported at the end actually tells you about the model.

