
Zero Knowledge
Oct 2, 2025
A Comparison of zkVM DSLs: Halo2, Zirgen, and Plonky3
Deep dive into ZK constraint systems: Halo2's PLONKish circuits, Zirgen's STARK compiler, and Plonky3's direct AIR authoring. Complete with Fibonacci examples.
Zero Knowledge
Jun 6, 2025

Notation
Overview
A typical STARK proof involves the following steps:
Adding Zero Knowledge
Masking the Witness Polynomials
Masking the DEEP Composition Polynomial
Why masking the DEEP composition polynomial is necessary
Adding entropy via masking
Choosing the masking degree $h$
Why this works
Toy Example
The Computation
Masking the Trace Polynomial
Conclusion
Acknowledgments
STARKs are one of the most exciting proof systems in the cryptography space today. They're transparent, scalable, post-quantum secure, and deeply mathematical. But one aspect of STARKs that can feel underexplained is how zero-knowledge is actually achieved. This blog post is here to fix that.
We dive into the elegant techniques behind zero-knowledge in STARKs. We'll learn why just adding randomness isn't enough and why the DEEP composition polynomial needs special attention.
Whether you're building a STARK prover or just trying to understand what happens under the hood, this post aims to give you the clearest and most accurate breakdown of how zero-knowledge is implemented in practice.
Before we get into the mechanics, let's define some recurring notation and parameters:
STARKs (Scalable Transparent ARguments of Knowledge) are cryptographic proof systems that allow a prover to convince a verifier that a certain computation was performed correctly, without revealing the computation's internal details or requiring the verifier to re-execute it. They are particularly attractive due to their transparency (no trusted setup) and post-quantum security.
At their core, STARKs reduce computational integrity to statements about polynomials over finite fields. The prover constructs a low-degree polynomial encoding the execution trace of a computation, commits to it using a Merkle tree, and then proves its validity through algebraic checks and interactive proofs. The verifier only needs to inspect a few values and Merkle paths to be convinced with high confidence.
Trace Generation — Evaluate the state of the computation at each step and record it in a trace table.
Polynomial Interpolation — Represent trace columns as low-degree polynomials.
The Quotient Polynomial — Define transition and boundary constraints using polynomial identities.
Low-Degree Extension (LDE) — Extend trace and quotient polynomials to a larger evaluation domain to enable probabilistic low-degree testing.
Commitment — Hash LDE evaluations into a Merkle tree to create a succinct commitment.
Trace Consistency Check — Perform evaluations outside the original domain to strengthen soundness by checking that the quotient polynomial is consistent with the constraints over the trace polynomials. Evaluate
and check that
where is a vanishing polynomial over the constraint domain.
FRI Protocol — Prove that the DEEP composition polynomial has low degree.
where
Verification — The verifier checks a small number of evaluations and Merkle paths to validate the proof.
Soundness ensures that false claims are rejected with high probability — but it doesn't prevent the verifier from learning something unintended about the prover’s witness. For full privacy, we want zero knowledge: the verifier should learn nothing about the internal computation beyond the fact that it was carried out correctly.
This is subtle in the context of STARKs. Even though no part of the witness is revealed directly, certain components — like evaluations in the Low-Degree Extension (LDE) domain, or out-of-domain (DEEP) queries — can unintentionally leak information.
To address this, modern STARK systems incorporate two distinct layers of masking:
Witness Masking — Before committing to the trace polynomials, the prover adds a random low-degree polynomial (drawn independently for each column) to each trace polynomial. These masks are chosen to vanish on the original evaluation domain , ensuring they don’t affect constraint satisfaction. But outside — especially on the larger evaluation domain used for the LDE — they act as effective noise, hiding the true values.
DEEP composition polynomial Masking — Even after masking the witness, the constraint system can leak information through the DEEP composition polynomial. Since this polynomial encodes evaluations over , and the verifier queries it at random points, it must also be masked. The prover adds a random low-degree polynomial to the final DEEP composition polynomial. Care must be taken to ensure that this additive mask maintains the degree bounds required for soundness and zero knowledge.
In summary: adding randomness alone isn’t enough — it must be structured randomness, carefully aligned with the algebraic structure of the proof system. Masking both the trace and the DEEP composition polynomial is essential for turning a sound STARK into a zero-knowledge STARK.
The verifier interacts with the trace polynomials in two key ways: during the FRI phase, which tests their low-degree structure over the evaluation domain, and during the trace consistency check, which evaluates constraint expressions at random points outside the evaluation domain. Both of these can potentially leak information about the execution trace.
To achieve zero knowledge, we mask each trace column polynomial by adding structured randomness that hides its values outside the original trace domain, while preserving correctness within it. This is done by multiplying a random low-degree polynomial with the vanishing polynomial of the trace domain.
Let denote the th trace polynomial interpolated over a domain . The masked version is defined as:
and is a random masking polynomial of degree less than .
This masking ensures the following:
Correctness over the trace domain: For any , we have , so the masked polynomial agrees with the original:
Thus, all transition and boundary constraints remain satisfied over the trace domain.
Randomness outside the domain: For any , the vanishing polynomial satisfies , so:
which is uniformly random in , provided is drawn uniformly. This ensures that the masked trace reveals nothing about the original trace at any queried point outside .
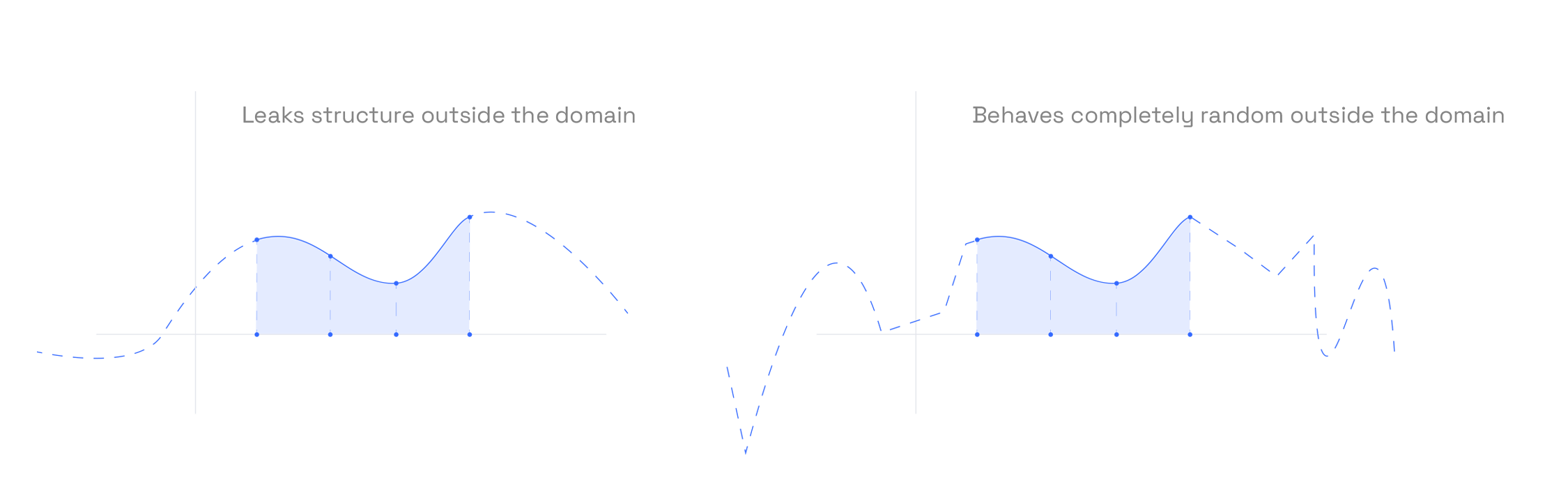
Even after masking the witness polynomials, zero-knowledge is not guaranteed. The issue arises during the FRI protocol, where the DEEP composition polynomial is tested for low degree. In this process, the verifier repeatedly folds to reduce its degree — and with each fold, some randomness from the original masking polynomials is also folded and lost.
Before applying the FRI protocol, the quotient polynomial must be brought into a form suitable for low-degree testing. Specifically, we require all polynomials passed to FRI to have degree of some power of two, which allows efficient recursive folding.
We begin by multiplying by an appropriate factor to increase its degree to the next power of two:
We then split into parts, where is the size of the trace domain. This ensures that each component has degree strictly less than , so that it can be committed and checked individually by FRI.
The decomposition is written as:
This structure allows the verifier to check all in parallel, using a single low-degree protocol with , and supports efficient Merkle tree commitments and folding.
After splitting into components , the prover then constructs the DEEP composition polynomial , which checks that:
This gives the final expression:
where the are verifier-chosen randomizers to bind the prover to all constraint evaluations simultaneously.
This polynomial is now subject to a low-degree check via FRI, and its correctness implies that all DEEP queries were answered consistently — across both the trace and the quotient parts.
Each trace polynomial is masked by a polynomial of the form , and the DEEP composition polynomial is computed from these masked traces. This means the randomness from is already embedded in .
However, FRI recursively folds — and in each fold, the degree is halved. Crucially, this also halves the effective entropy of the randomness inside . After several rounds, very little randomness remains, and the verifier may begin to observe statistical biases correlated with the underlying witness.
To prevent this leakage, we add fresh randomness directly to the polynomial before the FRI protocol begins.
Let be the size of the trace domain, and let be the masking degree used for the witness polynomials. We define the final quotient DEEP composition polynomial as:
where is a uniformly random masking polynomial of sufficiently high degree.
This fresh term does not affect any constraint checks (since FRI only verifies low-degree structure), but it ensures that the folded evaluations of remain statistically indistinguishable from random — even after multiple rounds of degree halving.
The degree of must be high enough to ensure that the prover’s responses remain statistically hidden even after many FRI rounds and trace consistency checks.
Let’s carefully account for the total number of degrees of freedom that could be leaked:
Therefore, to protect against all forms of leakage, the masking degree must satisfy:
Lemma: Let be masked trace polynomials as defined earlier, and suppose we split the quotient polynomial into components:
Let and be sets of DEEP and FRI query points respectively, with
Assume the masking degree satisfies the entropy bound:
Then the joint distribution of all queried values:
is statistically independent of the original (unmasked) witness polynomials .
In other words, even after observing all DEEP queries, their -shifts, and FRI spot-checks on the quotient components, the verifier learns nothing about the witness values — provided the masking degree is large enough.
To make the abstract steps of zero-knowledge STARKs concrete, we will walk through a small, fully specified example over a finite field. This example will serve as a running reference, illustrating each part of the protocol with concrete values.
We work over the prime field:
The multiplicative group has order 96 and is cyclic. Let be a generator. We define two multiplicative subgroups:
This mirrors a typical STARK setup: we interpolate the trace over , then extend it to for low-degree testing and constraint evaluation.
We model a simple computation: an 8-step Fibonacci sequence, defined recursively as:
With initial values:
Evaluating the recurrence gives the following execution trace:
| Step | |
|---|---|
| 0 | 89 |
| 1 | 90 |
| 2 | 82 |
| 3 | 75 |
| 4 | 60 |
| 5 | 38 |
| 6 | 1 |
| 7 | 39 |
These values represent the internal state of our computation over time. In a STARK proof, we will interpolate these values into a trace polynomial over the trace domain , then extend it to the larger domain as part of the low-degree extension (LDE) phase.
Let be the unique polynomial of degree less than 8 that satisfies:
Interpolating the Fibonacci values:
we obtain the trace polynomial:
This polynomial encodes the entire trace over , and will serve as the starting point for witness masking and constraint verification in the next steps.
To ensure zero knowledge, we mask the trace polynomial by adding a multiple of the vanishing polynomial over the trace domain . This preserves all values on , but randomizes evaluations elsewhere.
Let , the vanishing polynomial over , and let be a random masking polynomial. For this example, we choose:
where the degree is chosen as follows: the number of FRI queries is , the number of DEEP queries is , the splitting factor for the quotient polynomial is . With these numbers we can calculate the lower bound for as .
The masked trace polynomial is:
Substituting in the expression for , we get:
This polynomial agrees with at all points in , but appears pseudorandom at any , such as those used in trace consistency checks or FRI.
Zero‑knowledge in STARKs rests on two complementary masks:
Together, these ensure that a STARK proof reveals nothing beyond the truth of the statement, while preserving transparency, scalability, and post‑quantum security.
This post is based on and inspired by the excellent 2024 technical note “A Note on Adding Zero-Knowledge to STARKs” by Ulrich Haböck and Al Kindi. Their paper offers a clear and rigorous treatment of witness masking, quotient decomposition, and entropy accounting in small-field STARK systems. Many of the ideas and formal guarantees discussed here — especially those involving FRI, DEEP queries, and the structure of masking polynomials — are direct adaptations or intuitive explanations of results presented in that work.

